RF-DETR: Real-Time SOTA Object Detection, Instance Segmentation, and Keypoint Detection¶
RF-DETR is a real-time transformer architecture for object detection, instance segmentation, and keypoint detection (preview) developed by Roboflow. Built on a DINOv2 vision transformer backbone, RF-DETR achieves state-of-the-art accuracy–latency trade-offs: RF-DETR-L reaches 56.5 AP50:95 on COCO at 6.8 ms (NVIDIA T4, TensorRT FP16), and RF-DETR-2XL achieves 60.1 AP50:95 — the first real-time model to exceed 60 AP on COCO. Accepted at ICLR 2026.
RF-DETR uses a DINOv2 vision transformer backbone and supports object detection, instance segmentation, and keypoint detection (preview) in a single, consistent API. Core models (Nano through Large) and all code are released under the Apache 2.0 license; XL and 2XLarge detection models require rfdetr[plus] and are provided under PML 1.0.
Developed by Isaac Robinson, Peter Robicheaux, Fedor Popov, Deva Ramanan (CMU), and Neehar Peri (CMU) at Roboflow. If you use RF-DETR in your research, please cite:
@inproceedings{robinson2026rfdetr,
title = {RF-DETR: Real-Time Detection Transformer},
author = {Robinson, Isaac and Robicheaux, Peter and Popov, Fedor and Ramanan, Deva and Peri, Neehar},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2026},
url = {https://arxiv.org/abs/2511.09554}
}
Install¶
You can install and use rfdetr in a Python>=3.10 environment. For detailed installation instructions, including installing from source, and setting up a local development environment, check out our install page.



Quickstart¶
Tutorials¶
-
Train RF-DETR on a Custom Dataset. Video

End to end walkthrough of training RF-DETR on a custom dataset.
-
Deploy RF-DETR to NVIDIA Jetson. Article

Instructions for deploying RF-DETR on NVIDIA Jetson with Roboflow Inference.
-
Train and Deploy RF-DETR with Roboflow
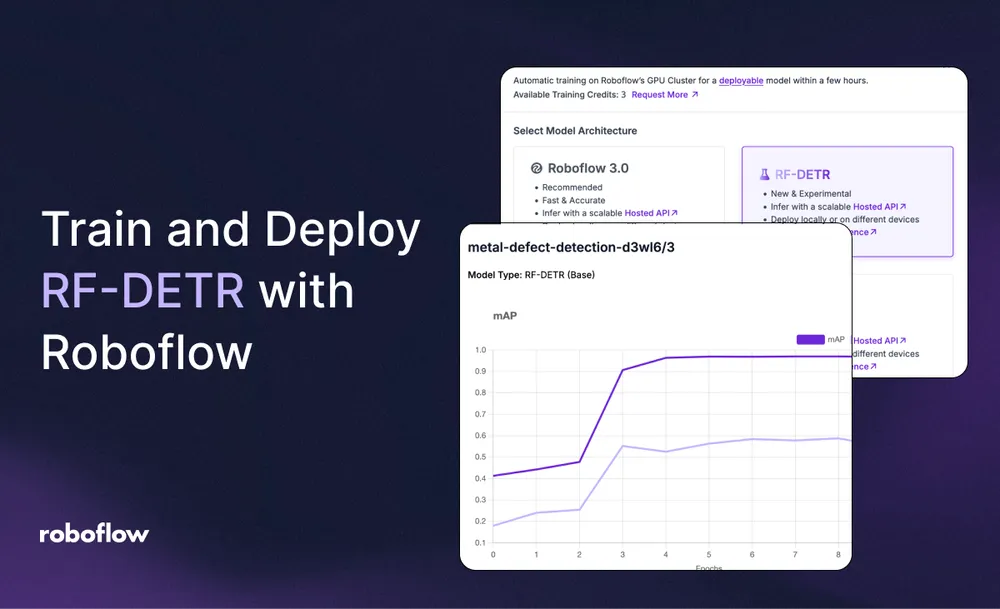
Cloud training and hardware deployment workflow using Roboflow.
Benchmarks¶
RF-DETR achieves the best accuracy–latency trade-off among real-time object detection and instance segmentation models. It also provides keypoint detection (preview) on COCO person keypoints. For detailed benchmark tables and methodology, check out our benchmarks page.
Detection¶
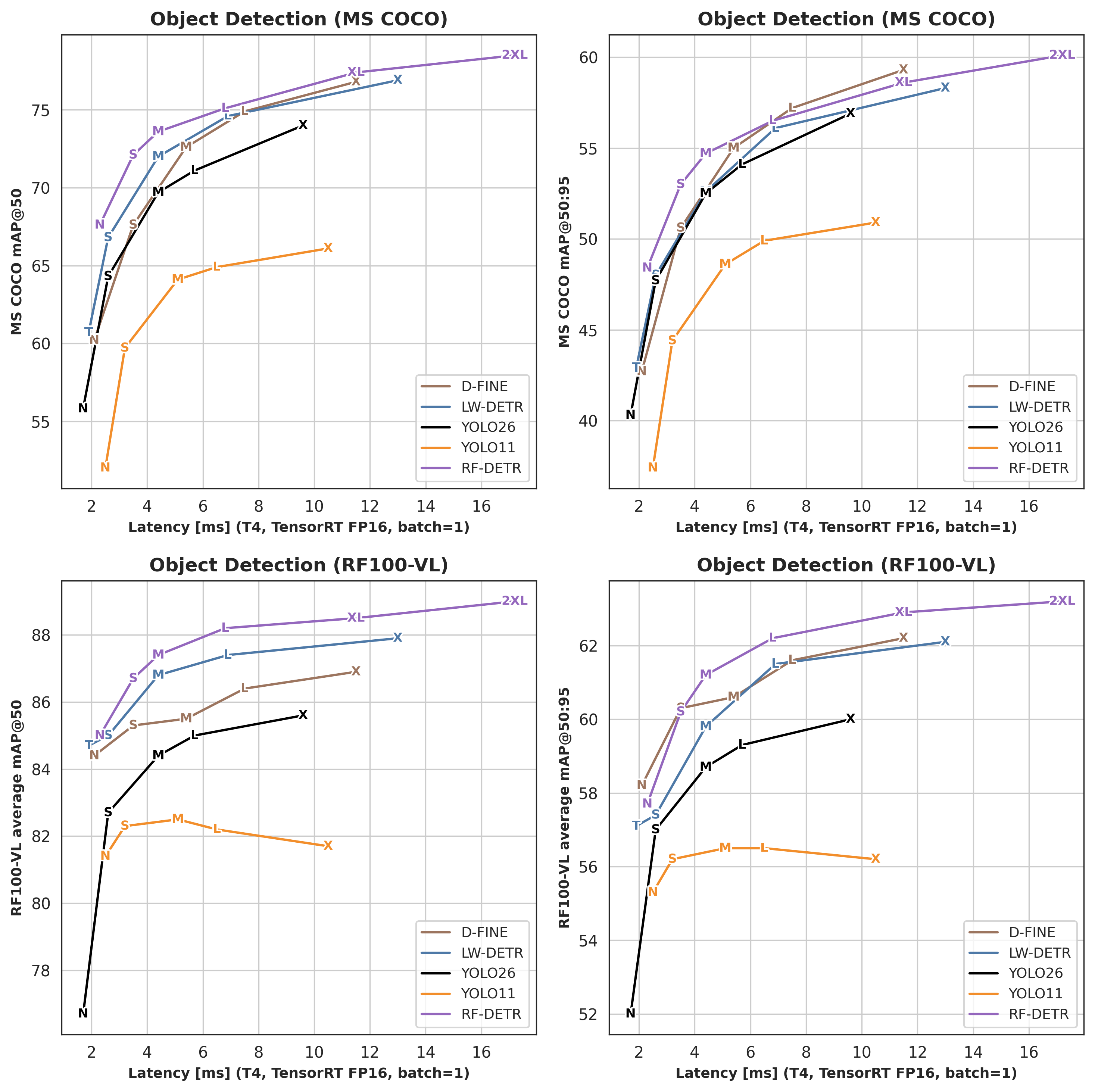
| Architecture | COCO AP50 | COCO AP50:95 | RF100VL AP50 | RF100VL AP50:95 | Latency (ms) | Params (M) | Resolution |
|---|---|---|---|---|---|---|---|
| RF-DETR-N | 67.6 | 48.4 | 85.0 | 57.7 | 2.3 | 30.5 | 384×384 |
| RF-DETR-S | 72.1 | 53.0 | 86.7 | 60.2 | 3.5 | 32.1 | 512×512 |
| RF-DETR-M | 73.6 | 54.7 | 87.4 | 61.2 | 4.4 | 33.7 | 576×576 |
| RF-DETR-L | 75.1 | 56.5 | 88.2 | 62.2 | 6.8 | 33.9 | 704×704 |
| RF-DETR-XL | 77.4 | 58.6 | 88.5 | 62.9 | 11.5 | 126.4 | 700×700 |
| RF-DETR-2XL | 78.5 | 60.1 | 89.0 | 63.2 | 17.2 | 126.9 | 880×880 |
Segmentation¶
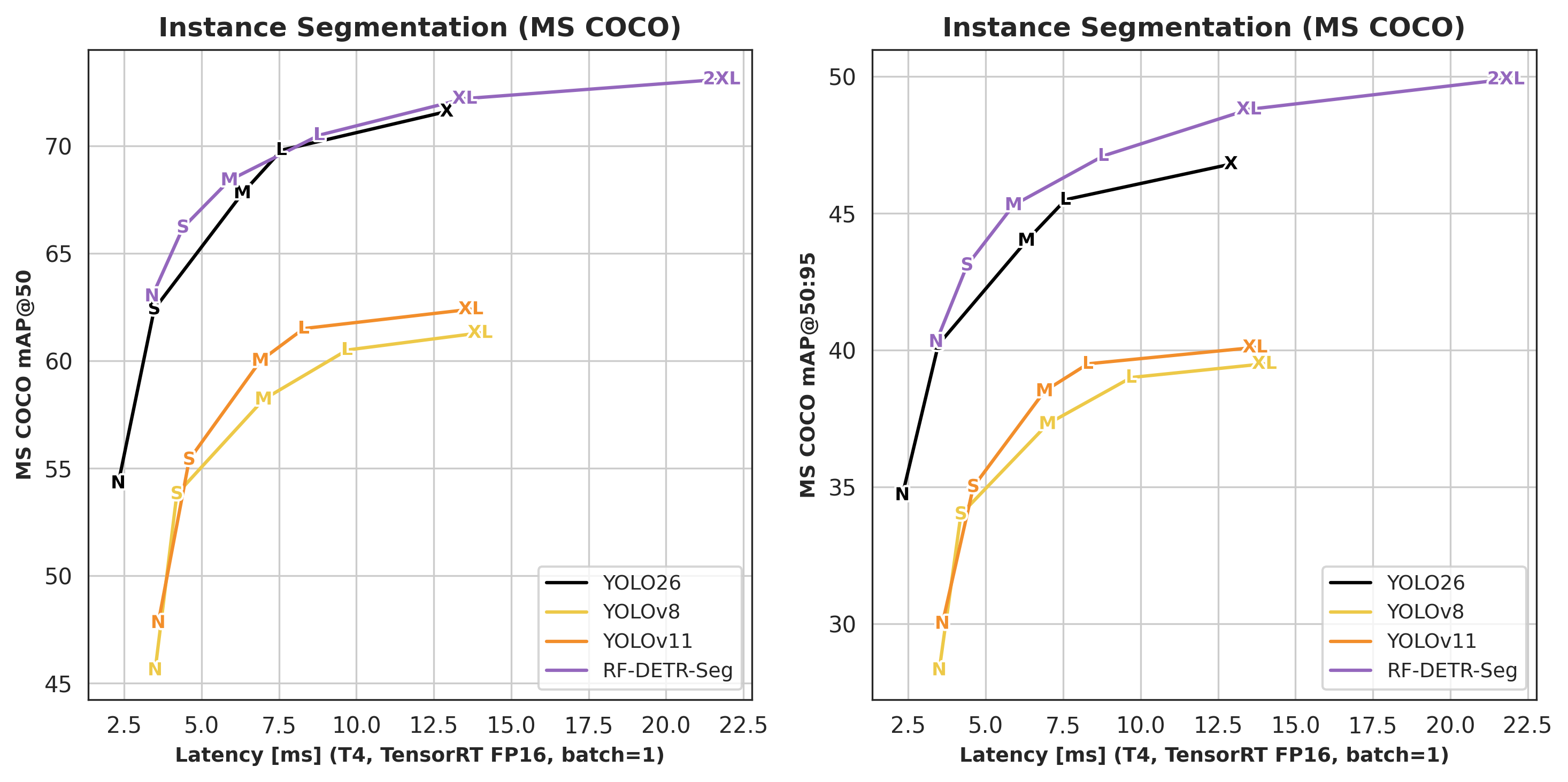
| Architecture | COCO AP50 | COCO AP50:95 | Latency (ms) | Params (M) | Resolution |
|---|---|---|---|---|---|
| RF-DETR-Seg-N | 63.0 | 40.3 | 3.4 | 33.6 | 312×312 |
| RF-DETR-Seg-S | 66.2 | 43.1 | 4.4 | 33.7 | 384×384 |
| RF-DETR-Seg-M | 68.4 | 45.3 | 5.9 | 35.7 | 432×432 |
| RF-DETR-Seg-L | 70.5 | 47.1 | 8.8 | 36.2 | 504×504 |
| RF-DETR-Seg-XL | 72.2 | 48.8 | 13.5 | 38.1 | 624×624 |
| RF-DETR-Seg-2XL | 73.1 | 49.9 | 21.8 | 38.6 | 768×768 |
Keypoints¶
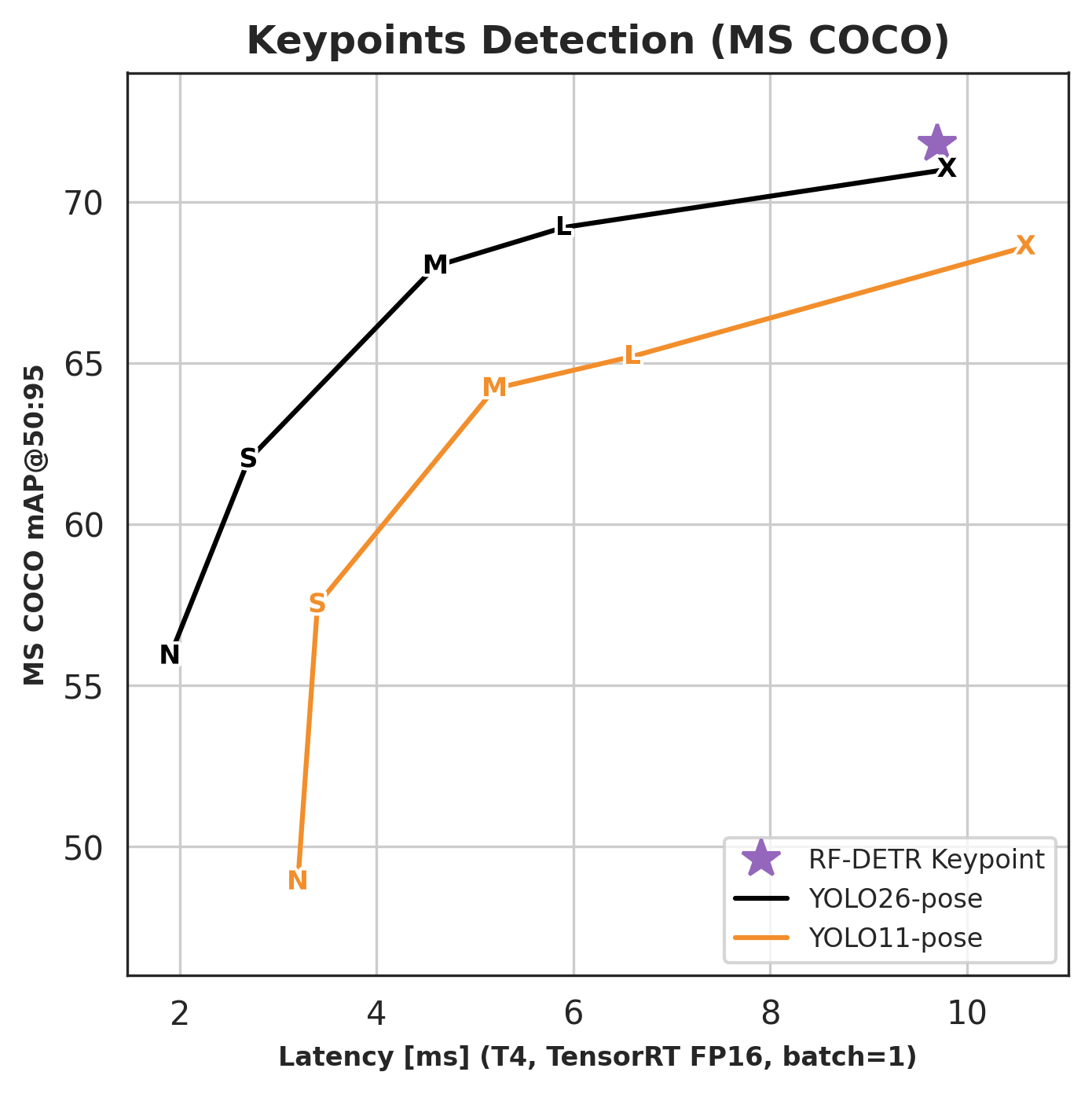
| Architecture | COCO AP50:95 | Latency (ms) | Params (M) | Resolution |
|---|---|---|---|---|
| RF-DETR Keypoint (Preview) | 71.8 | 9.7 | 126.4 | 576×576 |
Keypoint benchmarks report AP50:95 (OKS-based); this is the standard COCO keypoint comparison metric. For the full competitor comparison (YOLO11-pose, YOLO26-pose), see the Benchmarks page.
Frequently Asked Questions¶
What is RF-DETR? RF-DETR (Roboflow Detection Transformer) is a real-time object detection and instance segmentation model from Roboflow, accepted at ICLR 2026. It uses a DINOv2 vision transformer backbone and achieves state-of-the-art accuracy–latency trade-offs on COCO (60.1 AP50:95 for RF-DETR-2XL) and RF100-VL.
How does RF-DETR compare to YOLOv11? RF-DETR-L achieves 56.5 AP50:95 on COCO at 6.8 ms latency on an NVIDIA T4, outperforming YOLOv11x (54.7 AP) at lower latency. The DINOv2 backbone gives RF-DETR stronger performance on domain-shift benchmarks such as RF100-VL.
What GPU is required to train RF-DETR? A CUDA-capable GPU with at least 8 GB VRAM (e.g., NVIDIA RTX 3060, T4, A10) is recommended for fine-tuning. Smaller models (RF-DETR-N and RF-DETR-S) can fit in 6 GB VRAM with reduced batch size. CPU inference is supported for evaluation.
Which dataset formats does RF-DETR support?
RF-DETR supports COCO JSON and YOLO-format datasets (with dataset_file: "yolo"). Roboflow datasets export directly to both formats. Detection and segmentation datasets use the same format — the model variant determines the task.
Can RF-DETR run in real time? Yes. RF-DETR-N runs at 2.3 ms per frame on a T4 GPU (TensorRT FP16, batch 1), and RF-DETR-L at 6.8 ms — both well within real-time thresholds. ONNX and TFLite exports are available for edge deployment.
What is the difference between RF-DETR detection and segmentation models?
Detection models (e.g., RFDETRLarge) output bounding boxes. Segmentation models (e.g., RFDETRSegLarge) additionally output instance masks. Both share the same backbone and training API; segmentation adds a mask head and requires COCO-format segmentation annotations.
Does RF-DETR support keypoint detection?
RF-DETR Keypoint (Preview) detects 17 body keypoints per person on COCO, achieving 71.8 AP50:95 at 9.7 ms on NVIDIA T4. It is available in the rfdetr package as RFDETRKeypointPreview. See Run Keypoint Models for usage.
Is RF-DETR open source?
Yes. Core models (Nano through Large) and all training/inference code are released under the Apache 2.0 license. XLarge and 2XLarge models require the rfdetr[plus] package (PML 1.0 license).
How do I fine-tune RF-DETR on a custom dataset?
Instantiate a model and call model.train(...) with your dataset directory in COCO JSON or YOLO format. Example: model = RFDETRLarge(); model.train(dataset_dir='./dataset', epochs=50, batch_size=4). The model downloads pretrained weights automatically and resumes from the best checkpoint.
How do I export RF-DETR to ONNX or TensorRT?
Call model.export(format="onnx") after training or loading a checkpoint. ONNX export works on CPU and produces a single .onnx file compatible with ONNX Runtime and OpenCV DNN. For TensorRT deployment, first export to ONNX and then convert the .onnx model with TensorRT tooling or helpers such as trtexec; this requires TensorRT and a CUDA GPU.
Which RF-DETR model size should I use? RF-DETR-Nano (2.3 ms, 67.6 AP50 on COCO) is best for edge and real-time applications. RF-DETR-Large (6.8 ms, 56.5 AP50:95) offers the best accuracy–latency trade-off for server deployment. RF-DETR-2XLarge (17.2 ms, 60.1 AP50:95) maximizes accuracy when latency allows.
Checkpoint note: Current
RFDETRLargedefaults torf-detr-large-2026.pth. The olderrf-detr-large.pthcheckpoint is a legacy Large release kept for backward compatibility and has been superseded by the current release.