Benchmarks
RF-DETR is the first real-time model to exceed 60 AP on the Microsoft COCO benchmark alongside competitive performance at base sizes. It also achieves state-of-the-art performance on RF100-VL, an object detection benchmark that measures model domain adaptability to real world problems. RF-DETR is fastest and most accurate for its size when compared current real-time objection models.
On this page, we outline our results from our Microsoft COCO benchmarks, benchmarks across all seven categories in the RF100-VL benchmark, and notes from our benchmarking.
The table below shows the performance of RF-DETR, compared to other object detection models:
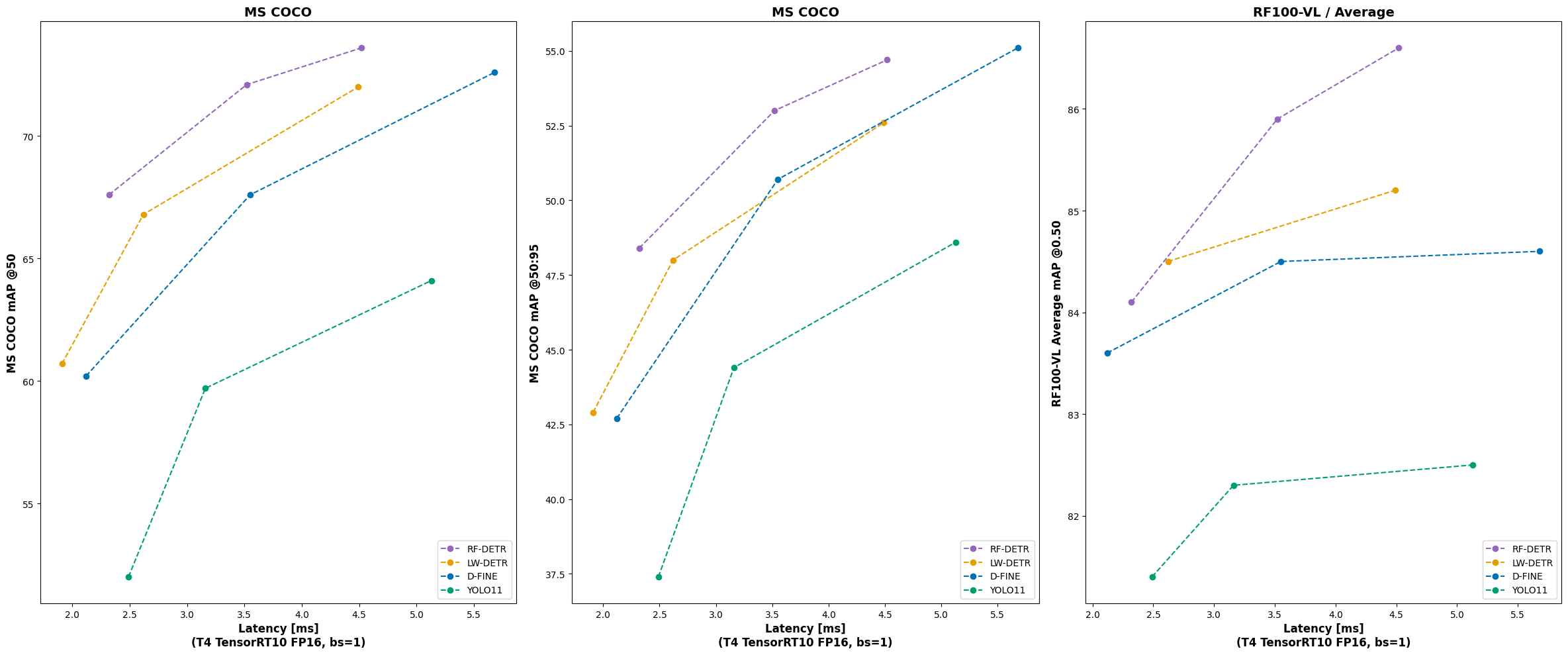
| Architecture | COCO AP50 | COCO AP50:95 | RF100VL AP50 | RF100VL AP50:95 | Latency (ms) | Params (M) |
|---|---|---|---|---|---|---|
| RF-DETR-N | 67.6 | 48.4 | 84.1 | 57.1 | 2.32 | 30.5 |
| RF-DETR-S | 72.1 | 53.0 | 85.9 | 59.6 | 3.52 | 32.1 |
| RF-DETR-M | 73.6 | 54.7 | 86.6 | 60.6 | 4.52 | 33.7 |
| YOLO11-N | 52.0 | 37.4 | 81.4 | 55.3 | 2.49 | 2.6 |
| YOLO11-S | 59.7 | 44.4 | 82.3 | 56.2 | 3.16 | 9.4 |
| YOLO11-M | 64.1 | 48.6 | 82.5 | 56.5 | 5.13 | 20.1 |
| YOLO11-L | 65.3 | 50.2 | x | x | 6.65 | 25.3 |
| YOLO11-X | 66.5 | 51.2 | x | x | 11.92 | 56.9 |
| LW-DETR-T | 60.7 | 42.9 | x | x | 1.91 | 12.1 |
| LW-DETR-S | 66.8 | 48.0 | 84.5 | 58.0 | 2.62 | 14.6 |
| LW-DETR-M | 72.0 | 52.6 | 85.2 | 59.4 | 4.49 | 28.2 |
| D-FINE-N | 60.2 | 42.7 | 83.6 | 57.7 | 2.12 | 3.8 |
| D-FINE-S | 67.6 | 50.7 | 84.5 | 59.9 | 3.55 | 10.2 |
| D-FINE-M | 72.6 | 55.1 | 84.6 | 60.2 | 5.68 | 19.2 |
We are actively working on RF-DETR Large and X-Large models using the same techniques we used to achieve the strong accuracy that RF-DETR Medium attains. This is why RF-DETR Large and X-Large is not yet reported on our pareto charts and why we haven't benchmarked other models at similar sizes. Check back in the next few weeks for the launch of new RF-DETR Large and X-Large models.